動的平均場理論入門1
概要
執筆中
論文へのリンク
問題設定
次のような深層ニューラルネットワークを考えよう。 \begin{align} f_\mu &= \frac{1}{\gamma\sqrt{N}} \boldsymbol{w}^L \cdot \phi(\boldsymbol{h}_\mu^L) \\ \boldsymbol{h}_\mu^{l+1} &= \frac{1}{\sqrt{N}} \boldsymbol{W}^l \phi(\boldsymbol{h}_\mu^l) \\ \boldsymbol{h}_\mu^1 &= \frac{1}{\sqrt{D}} \boldsymbol{W}^0 \boldsymbol{x}_\mu \end{align} ここで $\{\boldsymbol{x}_\mu\}_{\mu\in[P]}$ は $D$ 次元の入力データ、$\boldsymbol{h}^l_\mu$ は各データに対する第 $l$ 層のニューロンの $N$ 次元pre-activationベクトル、$f_\mu$ は最終層のスカラー出力、 $\boldsymbol{W}^l$ は第 $l$ 層の重み行列、$\phi$ は活性化関数、$\gamma$ は学習のレジームを調整するハイパーパラメータである。
このネットワークの重みを標準正規分布 $\mathcal{N}(0,1)$ で初期化して、フルバッチの勾配降下法で学習する。 すなわち誤差関数 $\mathcal{L} = \sum_\mu l(f_\mu, y_\mu)$ と学習率 $\eta$ を用いて、 \begin{align} \frac{d\boldsymbol{\theta}}{dt} &= -\eta\frac{\partial\mathcal{L}}{\partial\boldsymbol{\theta}} \end{align} と時間発展させる。 ただし $\boldsymbol{\theta} = \text{Vec}\{\boldsymbol{W}^0, \dots, \boldsymbol{W}^{L-1}, \boldsymbol{w}_L\}$ は学習する全ての重みをベクトル化したものである。
さて、ここで考えたいのは出力の学習ダイナミクス $f_\mu(t)$ (正確にいうと、全てのデータを使って重みを学習した時の、一つのデータ$\boldsymbol{x}_\mu$に対する出力$f_\mu$の学習ダイナミクス)である。 ナイーブに考えれば連鎖率から $\frac{\partial f_\mu}{\partial t}=\nabla_{\boldsymbol{\theta}=\boldsymbol{\theta}(t)}f_\mu \cdot \frac{d\boldsymbol\theta(t)}{dt}$ であり、これと上の式たちを使えば学習ダイナミクスを陽に計算できる。 というかこの計算を離散化して実行するのが通常の深層学習である。 しかし、理論的に解析する場合には、この方法は以下に示す理由から実用的でも本質的でもない。
ナイーブな方法の欠点
- ネットワークの各層の幅 $N$ を無限大にする極限では計算が無限に煩雑になってしまう
- 重みはランダムに初期化されるので、それぞれのrealizationごとにダイナミクスを調べても一般的な事実が得られない
これは「理解」に関するよくある議論の具体例だと思う。 要素の数がきわめて多くなったり相互作用がランダムになったりする場合には、それぞれの要素や相互作用を個別に調べるだけでは「理解」したことにはならない。 その代わりに巨視的な量やその期待値を計算することで初めて、系の典型的な性質がわかる。 動的平均場理論はまさにそのための手続きである。
この記事の目標と構成
上で説明した通り、いま手元にあるのは、出力の学習ダイナミクスを微視的なパラメータで記述した式 $\frac{\partial f_\mu}{\partial t}=\nabla_{\boldsymbol{\theta}=\boldsymbol{\theta}(t)}f_\mu \cdot \frac{d\boldsymbol\theta(t)}{dt}$ である。 それでは不便なので、パラメータではなく巨視変数であるカーネルで記述したい。 より正確には、パラメータのダイナミクスを一切参照せずに、カーネルと出力だけで閉じた時間発展方程式を得たい。
これを実現するために、まず出力のダイナミクスをカーネルで表示する。 この部分は割と簡単なので直後に説明する。 難しいのはそのカーネルの時間発展をパラメータを用いずに表す部分だ。 動的平均場理論の核心はここにあるので、計算の前にその気持ちを紹介する。 具体的な計算は非常に複雑なため、中間層が1層の場合でウォームアップしてから、一般の深層ネットワークの場合を説明する。
出力ダイナミクスをカーネルで表示する
$\frac{\partial f_\mu}{\partial t}=\sum_\alpha K_{\mu\alpha}^{NTK} (t,t) \Delta_\alpha (t)$ と表せる(クリックして表示)
NTKカーネル $K_{\mu\alpha}^{NTK} (t,s)$ とは、ニューラルネットワークの出力の勾配の内積である。 $$ K_{\mu\alpha}^{NTK} (t,s) = \gamma^2 \nabla_{\boldsymbol{\theta}(t)} f_\mu(t) \cdot \nabla_{\boldsymbol{\theta}(s)} f_\alpha(s) $$ 通常の定義では係数 $\gamma^2$ は付かないが、今の設定では出力 $f$ が $1/\gamma$ 倍されているのでそれを打ち消すために付けている。 NTKはNeural Tangent Kernelの略なのでNTカーネルと呼ぶのが正しいのかもしれないが、変な感じがするのでこの記事ではNTKカーネルと呼ぶ。
ではこのNTKカーネルを使って出力ダイナミクスが書けることを示そう。 \begin{align} \frac{\partial f_\mu}{\partial t} &= \nabla_{\boldsymbol{\theta}(t)}f_\mu(t) \cdot \frac{d\boldsymbol\theta(t)}{dt} \\ &= -\eta\nabla_{\boldsymbol{\theta}(t)}f_\mu(t) \cdot\frac{\partial\mathcal{L}}{\partial\boldsymbol{\theta}} \\ &= \eta\nabla_{\boldsymbol{\theta}(t)}f_\mu(t) \cdot \sum_\alpha \nabla_{\boldsymbol{\theta}(t)} f_\alpha(t) \Delta_\alpha(t) \\ &= \eta \sum_\alpha \nabla_{\boldsymbol{\theta}(t)}f_\mu(t) \cdot \nabla_{\boldsymbol{\theta}(t)} f_\alpha(t) \Delta_\alpha(t) \\ &= \frac{\eta}{\gamma^2}\sum_\alpha K_{\mu\alpha}^{NTK} (t,t) \Delta_\alpha(t) \end{align} ここで $\Delta_\mu(t) = \left.-\frac{\partial\mathcal{L}}{\partial f_\mu}\right|_{f_\mu=f_\mu(t)}$ は誤差関数の微分で、設定に応じて具体的に書き下せる。 例えばMSE lossの場合は $\Delta_\mu(t) = y_\mu - f_\mu(t)$ である。また、学習が $O_\gamma(1)$ で進むように以降では学習率を $\eta=\gamma^2$ とする。 以上から題意は示された。
この結果を味わってみよう。 $\Delta_\alpha(t)$ は出力 $f_\alpha(t)$ と教師データ $y_\alpha$ を使って簡単に書き下せるので、$f(t)$ の時間発展を考えるにあたっては何も問題ない。 逆にNTKカーネル $K_{\mu\alpha}^{NTK} (t,t)$ の方はパラメータに依存してしまっている。 したがってNTKカーネルの時間発展をパラメータを用いずに巨視変数だけで表すことができれば、出力が閉じた形で表せる。
また別の見方をすると、データ $\alpha$ に対する出力の学習がNTKカーネル $K_{\mu\alpha}^{NTK} (t,t)$ を通して他のデータ $\mu$ の学習に影響を与えているともいえる。
(クリックして非表示)
$K_{\mu\alpha}^{NTK} (t,s) = \sum_{l=0}^L \Phi_{\mu\alpha}^{l} (t,s)G_{\mu\alpha}^{l+1} (t,s)$ と表せる(クリックして表示)
特徴量カーネル $\Phi_{\mu\alpha}^{l} (t,s)$ と勾配カーネル $G_{\mu\alpha}^{l} (t,s)$ をそれぞれ次のように定義する。 \begin{align} \Phi_{\mu\alpha}^{l} (t,s) &:= \frac{1}{N} \phi(\boldsymbol{h}_\mu^l(t)) \cdot \phi(\boldsymbol{h}_\alpha^l(s)) \\ G_{\mu\alpha}^{l} (t,s) &:= \frac{1}{N} \boldsymbol{g}_\mu^l(t) \cdot \boldsymbol{g}_\alpha^l(s) \end{align} ただし勾配ベクトル $\boldsymbol{g}_\mu^l(t)$ の定義は次の通り。 $$ \boldsymbol{g}_\mu^l(t) := \gamma\sqrt{N} \frac{\partial f_\mu(t)}{\partial \boldsymbol{h}^l_\mu(t)} $$
直感的には、特徴量カーネル $\Phi_{\mu\alpha}^{l} (t,s)$ はデータ $\mu,\alpha$ それぞれに対する第 $l$ 層の活性化ベクトル $\phi \left( \boldsymbol{h}^l_\mu(t) \right),\phi \left( \boldsymbol{h}^l_\alpha(s) \right)$ の内積、 勾配ベクトル $\boldsymbol{g}_\mu^l(t)$ は第 $l$ 層の特徴量を変化させた時の出力の変化を表すベクトル、 勾配カーネル $G_{\mu\alpha}^{l} (t,s)$ はデータ $\mu,\alpha$ それぞれに対する第 $l$ 層の勾配ベクトルの内積である。
NTKカーネルの定義を変形して題意の式を得よう。 \begin{align} K_{\mu\alpha}^{NTK} (t,s) &= \gamma^2 \nabla_{\boldsymbol{\theta}(t)} f_\mu(t) \cdot \nabla_{\boldsymbol{\theta}(s)} f_\alpha(s) \\ &= \gamma^2 \sum_{l=0}^L \sum_{i,j=1}^N \nabla_{W_{ij}^l(t)} f_\mu(t) \cdot \nabla_{W_{ij}^l(s)} f_\alpha(s) \\ \end{align}
ここで \begin{align} \nabla_{W_{ij}^l(t)} f_\mu(t) &= \frac{\partial f_\mu(t)}{\partial \boldsymbol{h}_\mu^{l+1}(t)} \cdot \frac{\partial \boldsymbol{h}_\mu^{l+1}(t)}{\partial W_{ij}^l(t)} \\ &= \left(\frac{\partial f_\mu(t)}{\partial \boldsymbol{h}_\mu^{l+1}(t)}\right)_i \left(\frac{1}{\sqrt{N}} \phi(\boldsymbol{h}_\mu^l(t))\right)_j \\ &= \left(\frac{1}{\gamma\sqrt{N}}\boldsymbol{g}_\mu^{l+1}(t)\right)_i \left(\frac{1}{\sqrt{N}} \phi(\boldsymbol{h}_\mu^l(t))\right)_j \\ \end{align} を代入すると、
\begin{align} K_{\mu\alpha}^{NTK} (t,s) &= \gamma^2 \sum_{l=0}^L \left(\frac{1}{\gamma^2N}\sum_{i=1}^N \left(\boldsymbol{g}_\mu^{l+1}(t)\right)_i \left(\boldsymbol{g}_\alpha^{l+1}(s)\right)_i \right) \left(\frac{1}{N}\sum_{j=1}^N \left( \phi(\boldsymbol{h}_\mu^l(t))\right)_j \left( \phi(\boldsymbol{h}_\alpha^l(s))\right)_j \right) \\ &= \sum_{l=0}^L \frac{1}{N}\boldsymbol{g}_\mu^{l+1}(t)\cdot\boldsymbol{g}_\alpha^{l+1}(s) \frac{1}{N}\phi(\boldsymbol{h}_\mu^l(t))\cdot\phi(\boldsymbol{h}_\alpha^l(s)) \\ &= \sum_{l=0}^L \Phi_{\mu\alpha}^{l} (t,s)G_{\mu\alpha}^{l+1} (t,s) \\ \end{align} 以上から題意は示された。 ただし端の層には注意が必要。
入力層 $l=0$ について(クリックして表示)
$\nabla_{W_{ij}^0(t)} f_\mu(t) = \left(\frac{\partial f_\mu(t)}{\partial \boldsymbol{h}_\mu^{1}(t)}\right)_i \cdot \left(\frac{1}{\sqrt{D}} \boldsymbol{x}_\mu\right)_j \\$なので、 $$ \gamma^2 \nabla_{\boldsymbol{W}^0(t)} f_\mu(t) \cdot \nabla_{\boldsymbol{W}^0(s)} f_\alpha(s) = G_{\mu\alpha}^{1} (t,s) \frac{1}{D} \boldsymbol{x}_\mu \cdot \boldsymbol{x}_\alpha $$ よって一貫性のために $\Phi_{\mu\alpha}^{0} (t,s) = \frac{1}{D} \boldsymbol{x}_\mu \cdot \boldsymbol{x}_\alpha = K_{\mu\alpha}^{x}$ (入力のグラム行列)とする。
(クリックして非表示)
最終層 $l=L$ について(クリックして表示)
$\nabla_{\boldsymbol{w}^L(t)} f_\mu(t) = \frac{1}{\gamma\sqrt{N}} \phi(\boldsymbol{h}_\mu^L(t))$なので、 $$ \gamma^2 \nabla_{\boldsymbol{w}^L(t)} f_\mu(t) \cdot \nabla_{\boldsymbol{w}^L(s)} f_\alpha(s) = \Phi_{\mu\alpha}^{L} (t,s) $$ よって一貫性のために $G_{\mu\alpha}^{L+1} (t,s) = \boldsymbol{1}$ とする。
(クリックして非表示)
この結果を味わってみよう。 このDNNには層が $L$ 枚あって各層に $N^2$ 個のパラメータがあるので、パラメータの総数は大体 $N^2L$ である。 NTKカーネルは全てのパラメータに関する勾配の情報なので、愚直にやると計算量は $O(N^2L)$である。 層の幅 $N$ を無限大にする極限を考えたいのにとんでもない。
しかし、特徴量カーネルと勾配カーネルは両方とも $O(N)$ で計算できるので、導出した関係式を使えばNTKカーネルの計算が $O(NL)$ でできる。 ここからさらに $O(L)$ にするために動的平均場理論を使う。
(クリックして非表示)
以上から、特徴量カーネル $\Phi$ と勾配カーネル $G$ を使って出力の時間発展が次のように表せる。 $$ \frac{\partial f_\mu}{\partial t} = \sum_\alpha \sum_{l=0}^L \Phi_{\mu\alpha}^{l} (t,t)G_{\mu\alpha}^{l+1} (t,t) \Delta_\alpha(t) $$ 次の問題はカーネル $\Phi, G$ の時間発展を求めることだ。 各カーネルはそれぞれ特徴量ベクトルと勾配ベクトルで定義されているので、各ベクトルの時間発展を求めれば良い。
特徴量ベクトルと勾配ベクトルの時間発展
$\gamma_0 := \gamma/\sqrt{N}$ を使って時間発展は次のように書ける。$\boldsymbol{h}^{l+1}_\mu(t) = \frac{1}{\sqrt{N}}\boldsymbol{W}^{l}(0)\phi(\boldsymbol{h}^l_\mu(t)) + \gamma_0\int_0^t ds \sum_\nu\Delta_\nu(s) \boldsymbol{g}_\nu^{l+1}(s)\Phi_{\nu\mu}^{l} (s,t)$(クリックして表示)
これは特徴量ベクトル $\boldsymbol{h}^{l+1}_\mu$ の時間発展を、隣の層の特徴量ベクトル $\boldsymbol{h}^l_\nu$、同じ層の勾配ベクトル $\boldsymbol{g}_\nu^{l+1}$、隣の層の特徴量カーネル $\Phi_{\nu\mu}^{l}$ を使って表したものである。 これを導出しよう。 定義から $\boldsymbol{h}^{l+1}_\mu(t) = \frac{1}{\sqrt{N}}\boldsymbol{W}^{l}(t)\phi(\boldsymbol{h}^l_\mu(t))$ なので、パラメータ $\boldsymbol{W}^l(t)$ の時間発展を求めれば良い。
パラメータが満たす微分方程式を変形すると、 \begin{align} \frac{dW_{ij}^{l}(t)}{dt} &= -\gamma^2\nabla_{W_{ij}^{l}(t)} \mathcal{L}(f(t)) \\ &= \gamma^2\sum_\mu\Delta_\mu(t) \frac{\partial f_\mu}{\partial \boldsymbol{h}_\mu^{l+1}(t)} \cdot \frac{\partial \boldsymbol{h}_\mu^{l+1}(t)}{\partial W_{ij}^{l}(t)} \\ &= \gamma^2\sum_\mu\Delta_\mu(t) \left(\frac{\boldsymbol{g}_\mu^{l+1}(t)}{\gamma\sqrt{N}}\right)_i \left(\frac{\phi(\boldsymbol{h}_\mu^l(t))}{\sqrt{N}}\right)_j \\ &= \frac{\gamma}{N}\sum_\mu\Delta_\mu(t) \left(\boldsymbol{g}_\mu^{l+1}(t)\right)_i \left(\phi(\boldsymbol{h}_\mu^l(t))\right)_j \\ \therefore \boldsymbol{W}^{l}(t) &= \boldsymbol{W}^{l}(0) + \frac{\gamma}{N}\int_0^t ds \sum_\mu\Delta_\mu(s) \boldsymbol{g}_\mu^{l+1}(s)\phi(\boldsymbol{h}_\mu^l(s))^\top \\ \end{align}
これを $\boldsymbol{h}^{l+1}_\mu(t) = \frac{1}{\sqrt{N}}\boldsymbol{W}^{l}(t)\phi(\boldsymbol{h}^l_\mu(t))$ に代入して目的の式を得る。 流れをまとめると、第 $l$ 層と第 $l+1$ 層の特徴量ベクトルの関係式にパラメータの時間発展を代入して、特徴量ベクトルの時間発展を求めている。
(クリックして非表示)
$ \left\{ \begin{aligned} &\boldsymbol{g}^{l}_\mu(t) = \dot{\phi}(\boldsymbol{h}^l_\mu(t)) \odot \boldsymbol{z}^{l}_\mu(t) \\ &\boldsymbol{z}^{l}_\mu(t) = \frac{1}{\sqrt{N}}\boldsymbol{W}^{l\top}(0)\boldsymbol{g}^{l+1}_\mu(t) + \gamma_0\int_0^t ds \sum_\nu\Delta_\nu(s) \phi(\boldsymbol{h}_\nu^{l}(s))G_{\nu\mu}^{l+1} (s,t) \end{aligned} \right. $(クリックして表示)
前項の流れを踏襲したいので、まず勾配ベクトルの漸化式を求める。 特徴量ベクトルの場合は定義から明らかに順方向の漸化式が得られた。 勾配ベクトルの場合は微分の連鎖率から逆方向の漸化式が得られる。 \begin{align} \left(\boldsymbol{g}^{l}_\mu(t)\right)_i &= \gamma\sqrt{N}\left(\frac{\partial f_\mu}{\partial \boldsymbol{h}_\mu^{l}(t)}\right)_i \\ &= \gamma\sqrt{N}\frac{\partial f_\mu}{\partial \boldsymbol{h}_\mu^{l+1}(t)} \cdot \frac{\partial \boldsymbol{h}_\mu^{l+1}(t)}{\left(\partial \boldsymbol{h}_\mu^{l}(t)\right)_i} \\ &= \sum_j \left(\boldsymbol{g}_\mu^{l+1}(t)\right)_j \frac{\partial \left(\boldsymbol{h}_\mu^{l+1}(t)\right)_j}{\partial \left(\boldsymbol{h}_\mu^{l}(t)\right)_i} \\ &= \sum_j \left(\boldsymbol{g}_\mu^{l+1}(t)\right)_j \frac{1}{\sqrt{N}}W^l_{ji}(t)\dot{\phi}(\boldsymbol{h}_\mu^{l}(t))_i \\ &= \frac{1}{\sqrt{N}}\dot{\phi}(\boldsymbol{h}_\mu^{l}(t))_i\left(\boldsymbol{W}^{l\top}(t)\boldsymbol{g}_\mu^{l+1}(t)\right)_i \\ \therefore \boldsymbol{g}^{l}_\mu(t) &= \dot{\phi}(\boldsymbol{h}_\mu^{l}(t)) \odot \boldsymbol{z}^{l}_\mu(t) \end{align} ただし $\boldsymbol{z}^{l}_\mu(t) = \frac{1}{\sqrt{N}}\boldsymbol{W}^{l\top}(t)\boldsymbol{g}^{l+1}_\mu(t)$ 。 これは誤差逆伝播の計算と全く同じ。 こうして求めた漸化式に前項で求めた $\boldsymbol{W}^l(t)$ を代入して目的の式を得る。
(クリックして非表示)
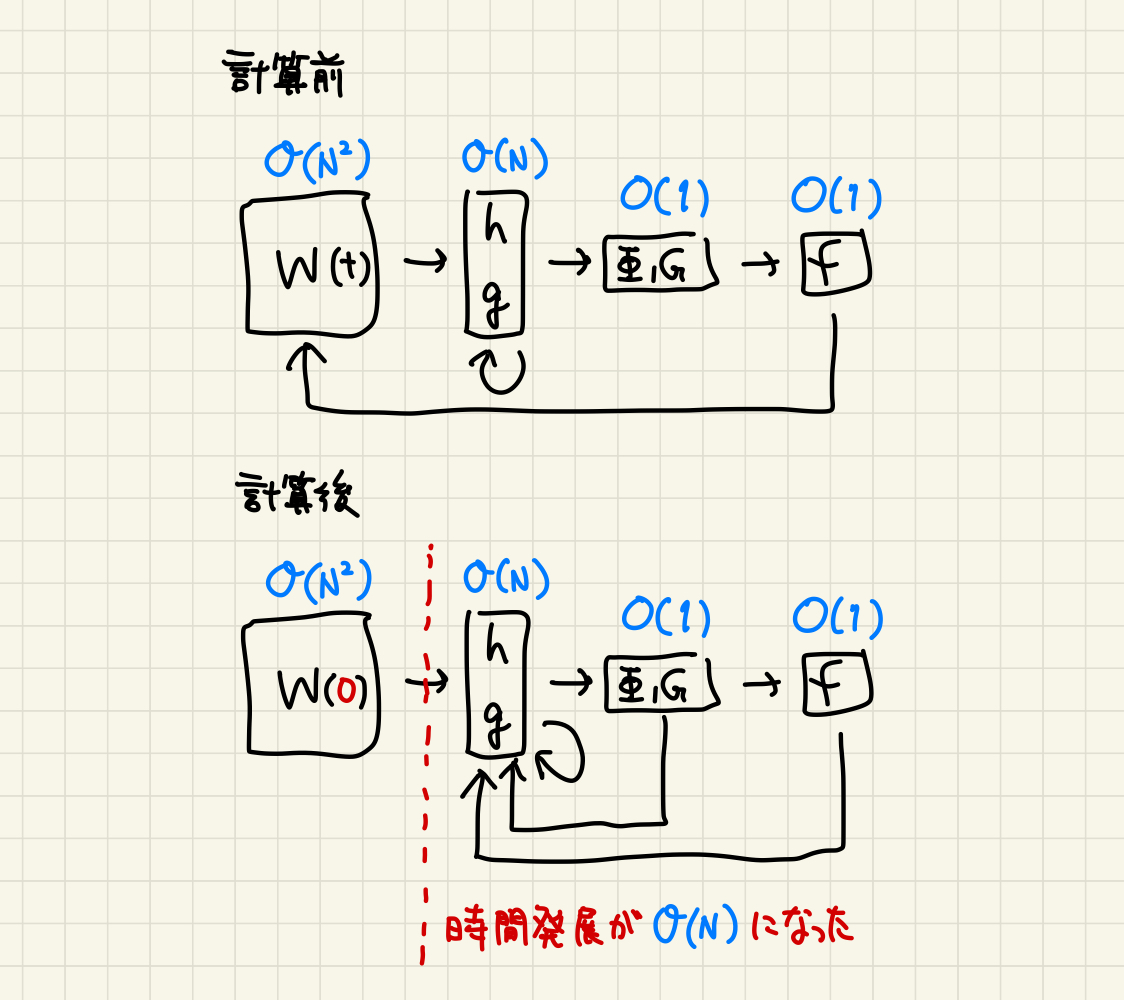
注目するべきは、学習によって時間変化するパラメータ $\boldsymbol{W}^{l}(t)$ はもはや登場せず、パラメータの寄与は初期値 $\boldsymbol{W}^{l}(0)$ のみに現れている点だ。 別の言い方をすれば、各ベクトルの初期化だけにランダムネスが現れ、時間発展の方は出力とベクトルとカーネルで閉じた形になっている。 変数の依存関係を図1にまとめた。 $\boldsymbol{W}^{l}(t)$ の分布は非常に複雑な一方で初期値 $\boldsymbol{W}^{l}(0)$ の分布はこちらが指定できるため、これは縁起の良い形だ。
動的平均場理論
前置きが長くなったが、ここからが本題。 この記事の目標は幅無限大の極限で出力の学習ダイナミクスを理論解析することだった。 素朴に考えるとパラメータの時間発展が主役になってしまうが、ここまでの計算によってパラメータの初期値とベクトルの時間発展で記述できるようになった。 残る問題は①パラメータの初期化にランダムネスがあることと、②ベクトルの長さが無限大になってしまうこと。 動的平均場理論を用いて、①ガウス積分で期待値を取る方法と②決定論的な平均場との相互作用を導入する方法とでそれぞれ解決する。
動的平均場理論(Dynamical Mean Field Theory, DMFT)とは、1.クエンチした確率変数が 2.大量に集まった系での、 3.巨視変数の 4.ダイナミクスを求める方法である。
- 確率変数がクエンチしているとは、注目する時間発展の間に変化しないという意味である。 例えばリカレントネットワークの結合をランダムに定めて、その結合のもとでニューロンの状態を時間発展させる系や、フィードフォワードネットワークの初期重みをランダムに定めて出力を学習する系(今の系はこれ)が考えられる。 後者の場合は重みが時間発展するが、確率性があるのは重みの初期化だけで、それが決まれば残りは決定論的に発展するという点がポイント。
- クエンチした独立な確率変数が大量に集まる時、自己平均性が期待できる。 この辺あやふやなので後で書き換えるかも。
- 巨視的な変数は、Ising系なら磁化、リカレントネットワークなら平均活動度、フィードフォワードネットワークなら上で定義した特徴量カーネル $\Phi^l$ と勾配カーネル $G^l$ などのように、微視的な変数を平均して求める変数のこと。 オーダーパラメータともいう。
- 例えばIsingモデルの平均場近似とは違って、ダイナミクスを記述することから動的という名前がついている(と僕は思っている)。 したがって求めるべき対象は、巨視変数のダイナミクスを閉じた形で定める時間発展方程式や、相関関数のセルフコンシステント方程式である。
ウォームアップ:L=1の場合
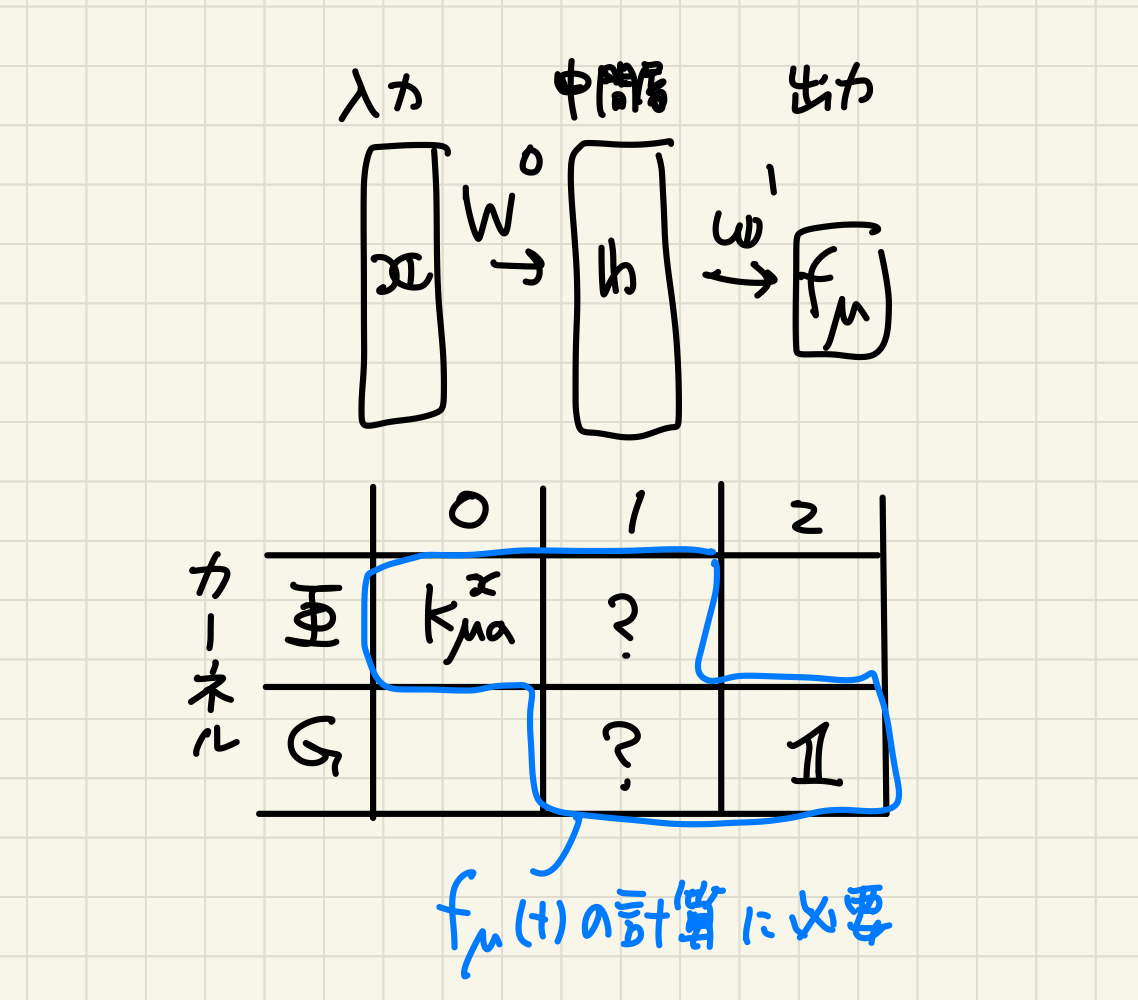
この節では中間層が1層の場合を考える(図2)。 出力のダイナミクスを記述するにあたって必要なのは $\Phi_{\mu\alpha}^0, \Phi_{\mu\alpha}^1, G_{\mu\alpha}^1, G_{\mu\alpha}^2$ だ。 このうち端の二つは定義から $\Phi_{\mu\alpha}^0 = K_{\mu\alpha}^x, G_{\mu\alpha}^2 = \boldsymbol{1}$ となるので、中の二つが問題となる。
定義から $\Phi_{\mu\alpha}^1 = \frac{1}{N} \phi(\boldsymbol{h}_\mu) \cdot \phi(\boldsymbol{h}_\alpha), G_{\mu\alpha}^1 = \frac{1}{N} \boldsymbol{g}_\mu \cdot \boldsymbol{g}_\alpha$ なので、 $\boldsymbol{h}_\mu(t), \boldsymbol{g}_\mu(t)$ を計算すれば良い(ここで層の添字 $l$ は省略している)。 上でやった計算を境界条件に気をつけて再現すれば、 \begin{align} \boldsymbol{h}_\mu(t) &= \frac{1}{\sqrt{D}} \boldsymbol{W}^{0}(t)\boldsymbol{x}_\mu \\ &= \frac{1}{\sqrt{D}}\left(\boldsymbol{W}^{0}(0) + \frac{\gamma}{\sqrt{ND}}\int_0^t ds \sum_\nu\Delta_\nu(s) \boldsymbol{g}_\nu(s)\boldsymbol{x}_\nu^\top\right)\boldsymbol{x}_\mu \\ &= \boldsymbol{\chi}_\mu + \gamma_0\int_0^t ds \sum_\nu\Delta_\nu(s) \boldsymbol{g}_\nu(s)K_{\mu\nu}^x \\ \boldsymbol{g}_\mu(t) &= \boldsymbol{z}(t) \odot \dot\phi(\boldsymbol{h}_\mu(t)) \\ \boldsymbol{z}(t) &= \boldsymbol{w}^{1}(t)\\ &= \boldsymbol{\xi} + \gamma_0\int_0^t ds \sum_\nu\Delta_\nu(s) \phi(\boldsymbol{h}_\nu(s))\\ \end{align} となる。 ただし第一項をそれぞれ $\boldsymbol{\chi}_\mu := \frac{1}{\sqrt{D}}\boldsymbol{W}^{0}(0)\boldsymbol{x}_\mu, \boldsymbol{\xi} := \boldsymbol{w}^{1}(0)$ とおいた。 どちらも $t$ に依存しない定数であることに注意しよう。 ネタバレしておくと一般の $L$ ではこれが時間変化するようになって大変になる。
パラメータ初期化のランダムネスは $\boldsymbol{\chi}_\mu$ と $\boldsymbol{\xi}$ にのみ現れていて、それがベクトル $\boldsymbol{h}_\mu(t), \boldsymbol{g}_\mu(t)$ に影響し、カーネル $\Phi_{\mu\alpha}^1, G_{\mu\alpha}^1$ に影響している。 この微視的なランダムネスをまともに扱うと $O(N)$ になってしまうが、知りたいのはカーネル $\Phi_{\mu\alpha}^1, G_{\mu\alpha}^1$ であることを念頭に置いて、これを回避する。 抽象的には、パラメータ初期値という微視変数からカーネルという巨視変数に変数変換をすることで測度の集中が起きるということ。 具体的には、 $\boldsymbol{W}^0(0), \boldsymbol{w}^1(0)$ のモーメント生成関数を変形することで、カーネル $\Phi_{\mu\alpha}^1, G_{\mu\alpha}^1$ の $O(1)$ の計算方法を入手するということ。
モーメント生成関数 $Z(j)$ の導入(クリックして表示)
以降の計算で主役になるのはモーメント生成関数 (モーメント母関数)だ。 一般に、確率変数 $x$ のモーメント生成関数 $Z_x(j)$ は次のように定義される。 \begin{align} Z_x(j) &= \langle \exp(jx) \rangle \\ &= \int P(x) \exp(jx) dx \end{align} ただし $P(x)$ は $x$ の確率分布である。 なぜモーメント生成関数と呼ぶかというと $j$ で $k$ 回微分したときに $x$ の $k$ 次モーメントが現れるからだが、その性質は今回の記事では使わない。 重要なのは、$Z_x(j)$ が $P(x)$ の完全な情報を持っているという点だ。 以降の計算では $W(0)$ の確率性に注目してモーメント生成関数を定義した後に、それを変形し、新しく現れたモーメント生成関数を見て平均場の確率分布が得られたとみなす。
モーメント生成関数と分配関数の関係(クリックして表示)
モーメント生成関数を $Z$ で表すのはある意味で分配関数と同一視できるからだ。 それを説明する。 統計力学では分配関数 $Z$ は次のように定義される。 \begin{align} Z(\beta) &= \int \exp(-\beta E(x)) dx \\ &= \int \rho(E)\exp(-\beta E) dE \end{align} ただし $\beta$ は逆温度であり、$\rho(E)$ はエネルギー $E$ の状態密度である。
モーメント生成関数の定義と見比べると、 \begin{align} x &\leftrightarrow E \\ P(x) &\leftrightarrow \rho(E) \\ j &\leftrightarrow -\beta \\ \end{align} という対応があることがわかる。 ただしモーメント生成関数の方は高次元の $x$ と$j$ を考えうるのに対して、分配関数はそうではないと思うので、完璧な対応とはいえないかもしれない。
(クリックして非表示)
(クリックして非表示)
$\boldsymbol{W}^0(0), \boldsymbol{w}^1(0)$ に関するモーメント生成関数を定義する。 $$ Z[\{\boldsymbol{j}_\mu\}_{\mu \in [P]}, \boldsymbol{v}] := \left\langle \exp\left(\sum_\mu \boldsymbol{j}_\mu \cdot \boldsymbol{\chi}_\mu + \boldsymbol{v}\cdot\boldsymbol{\xi}\right)\right\rangle_{\boldsymbol{W}^0(0), \boldsymbol{w}^1(0)} $$
恒等式を挟んで変形すると次のようになる。(クリックして表示)
いま $\boldsymbol{\chi}_\mu = \frac{1}{\sqrt{D}}\boldsymbol{W}^0(0)\boldsymbol{x}_\mu$ という関係式がある。 これを上の式に代入するのではなく、$\delta$関数として表現し、さらにそれをフーリエ変換した恒等式を用いる。 すなわち \begin{align} 1 &= \int d\boldsymbol{\chi}_\mu \delta\left(\boldsymbol{\chi}_\mu - \frac{1}{\sqrt{D}}\boldsymbol{W}^0(0)\boldsymbol{x}_\mu\right)\\ &= \int \frac{d \boldsymbol{\chi}_\mu d \boldsymbol{\hat\chi}_\mu}{(2\pi)^N}\exp\left(i\boldsymbol{\hat\chi}_\mu\left(\boldsymbol{\chi}_\mu - \frac{1}{\sqrt{D}}\boldsymbol{W}^0(0)\boldsymbol{x}_\mu\right)\right) \end{align} を全ての $\mu$ について両辺に掛ける。
$\xi$ についても同様に、 $$ 1=\int \frac{d \boldsymbol{\xi} d \boldsymbol{\hat\xi}}{(2\pi)^N} \exp\left(i\boldsymbol{\hat\xi} \left(\boldsymbol{\xi} - \boldsymbol{w}^1(0)\right)\right) $$ を両辺に掛ける。
こうすることで、元は $\boldsymbol{W}^0(0), \boldsymbol{w}^1(0)$ の関数だった $\boldsymbol{\chi}_\mu, \boldsymbol{\xi}$ が独立な確率変数として扱えるようになり、 $\boldsymbol{W}^0(0), \boldsymbol{w}^1(0)$ の寄与は陽に現れるようになった。 その結果パラメータ初期値に関する期待値が取りやすくなった(本当はL=1の場合は元から取りやすかったが、一般のLでは真に取りやすくなる)。 著者によるとこういう形式をMSRDJ formalismというらしい。 MSRDJ経路積分という経路積分表示で似たような変形をするからだと思う。
(クリックして非表示)
\begin{align} Z[\{\boldsymbol{j}_\mu\}_{\mu \in [P]}, \boldsymbol{v}] = \int \left(\prod_\mu \frac{d \boldsymbol{\chi}_\mu d \boldsymbol{\hat\chi}_\mu}{(2\pi)^N}\right) \frac{d \boldsymbol{\xi} d \boldsymbol{\hat\xi}}{(2\pi)^N} \left\langle\exp\left( \sum_\mu i\boldsymbol{\hat\chi}_\mu \left(\boldsymbol{\chi}_\mu - \frac{1}{\sqrt{D}}\boldsymbol{W}^0(0)\boldsymbol{x}_\mu\right) \right. \right.&\\ \left.\left. + i\boldsymbol{\hat\xi} \left(\boldsymbol{\xi} - \boldsymbol{w}^1(0)\right) + \sum_\mu \boldsymbol{j}_\mu \cdot \boldsymbol{\chi}_\mu + \boldsymbol{v}\cdot\boldsymbol{\xi} \right)\right\rangle_{\boldsymbol{W}^0(0), \boldsymbol{w}^1(0)}& \end{align}
$\boldsymbol{W}^0(0), \boldsymbol{w}^1(0)$ についてガウス積分すると $\boldsymbol{\chi}_\mu, \boldsymbol{\xi}$ のモーメント生成関数が得られる。(クリックして表示)
$x\sim \mathcal{N}(0, \sigma^2)$ のガウス変数について、次の公式が成り立つ。 \begin{align} \langle \exp(jx) \rangle_x &= \int dx \exp\left(-\frac{x^2}{2\sigma^2} + jx\right)\\ &= \int dx \exp\left(-\frac{1}{2\sigma^2}(x - j\sigma^2)^2 + \frac{j^2\sigma^2}{2}\right)\\ &= \exp\left(\frac{j^2\sigma^2}{2}\right) \end{align} これを念頭に置いて高次元の場合も積分しよう。
\begin{align} \left\langle \exp\left(-\sum_\mu \frac{i\boldsymbol{\hat\chi}_\mu \boldsymbol{W}^0(0) \boldsymbol{x}_\mu}{\sqrt{D}}\right) \right\rangle_{\boldsymbol{W}^0(0)} &= \prod_{ij}\left\langle\exp\left(-\sum_\mu\frac{i(\hat\chi_\mu)_i W^0_{ij}(0) (x_\mu)_j}{\sqrt{D}}\right)\right\rangle_{W^0_{ij}(0)} \\ &= \prod_{ij}\exp\left(-\frac{1}{2D}\sum_{\mu\alpha} (\hat\chi_\mu)_i(\hat\chi_\alpha)_i(x_\mu)_j(x_\alpha)_j\right) \\ &= \exp\left(-\frac{1}{2D}\sum_{\mu\alpha} \boldsymbol{\hat\chi}_\mu \cdot \boldsymbol{\hat\chi}_\alpha \boldsymbol{x}_\mu \cdot \boldsymbol{x}_\alpha\right) \\ &= \exp\left(-\frac{1}{2}\sum_{\mu\alpha} \boldsymbol{\hat\chi}_\mu \cdot \boldsymbol{\hat\chi}_\alpha K^x_{\mu\alpha}\right) \\ \left\langle \exp\left(-i\boldsymbol{\hat\xi} \boldsymbol{w}^1(0)\right) \right\rangle_{\boldsymbol{w}^1(0)} &= \prod_{i}\left\langle\exp\left(-i\hat\xi_i w^1_i(0)\right)\right\rangle_{w^1_i(0)} \\ &= \prod_{i}\exp\left(-\frac{1}{2}\hat\xi_i^2\right) \\ &= \exp\left(-\frac{1}{2}|\boldsymbol{\hat\xi}|^2\right) \end{align} 上の二式を代入すれば $\boldsymbol{W}^0(0), \boldsymbol{w}^1(0)$ のガウス積分が完了する。 こうしてパラメータの初期値を変数変換してベクトル $\boldsymbol{\chi}_\mu, \boldsymbol{\xi}$ の確率性に注目したモーメント生成関数が手に入った。
(クリックして非表示)
\begin{align} Z[\{\boldsymbol{j}_\mu\}_{\mu \in [P]}, \boldsymbol{v}] = \int \left(\prod_\mu \frac{d \boldsymbol{\chi}_\mu d \boldsymbol{\hat\chi}_\mu}{(2\pi)^N}\right) \frac{d \boldsymbol{\xi} d \boldsymbol{\hat\xi}}{(2\pi)^N} \exp\left( \sum_\mu i\boldsymbol{\hat\chi}_\mu \cdot \boldsymbol{\chi}_\mu - \frac{1}{2}\sum_{\mu\alpha} \boldsymbol{\hat\chi}_\mu \cdot \boldsymbol{\hat\chi}_\alpha K_{\mu\alpha}^x \right. &\\ \left. + i\boldsymbol{\hat\xi} \cdot \boldsymbol{\xi} - \frac{1}{2}|\boldsymbol{\hat\xi}|^2 + \sum_\mu \boldsymbol{j}_\mu \cdot \boldsymbol{\chi}_\mu + \boldsymbol{v}\cdot\boldsymbol{\xi} \right) & \end{align}
このモーメント生成関数をよく見ると、独立な $N$ 個の1体問題の積に分解できることがわかる。 すなわち、 $$ \left\{ \begin{align} Z[\{\boldsymbol{j}_\mu\}_{\mu \in [P]}, \boldsymbol{v}] &= \prod_{i=1}^N Z_1[\{j^\mu_i\}_{\mu \in [P]}, v_i] \\ Z_1[\{j^\mu\}_{\mu \in [P]}, v] &= \int \left(\prod_\mu \frac{d\chi_\mu d \hat\chi_\mu}{2\pi}\right)\frac{d\xi d\hat\xi}{2\pi} \exp\left(f_1\left(\{\chi_\mu\}, \xi\right) \right) \\ f_1\left(\{\chi_\mu\}, \xi\right) &= \sum_\mu i\hat\chi_\mu\chi_\mu - \frac{1}{2}\sum_{\mu\alpha} \hat\chi_\mu \hat\chi_\alpha K_{\mu\alpha}^x + i\hat\xi \xi - \frac{1}{2}\hat\xi^2 + \sum_\mu j^\mu \chi_\mu + v \xi \end{align} \right. $$ と書ける。$\chi_\mu, \xi, j^\mu, v$ はいずれもスカラーである。
1体のモーメント生成関数 $Z_1$ は $i$ によらない点に注目しよう。 N体のモーメント生成関数 $Z$ がidenticalな $Z_1$ の積で書けるということは、ベクトル $\boldsymbol{\chi}_\mu, \boldsymbol{\xi}$ の各成分が独立同分布に従う確率変数であることを意味する。
しかし、これは $\boldsymbol{h}_\mu(t), \boldsymbol{g}_\mu(t)$ の各成分が独立であることを意味しない。 表式を再掲すると、 $$ \left\{ \begin{align} \boldsymbol{h}_\mu(t) &= \boldsymbol{\chi}_\mu + \gamma_0\int_0^t ds \sum_\nu\Delta_\nu(s) \boldsymbol{g}_\nu(s)K_{\mu\nu}^x \\ \boldsymbol{g}_\mu(t) &= \boldsymbol{z}(t) \odot \dot\phi(\boldsymbol{h}_\mu(t)) \\ \boldsymbol{z}(t) &= \boldsymbol{\xi} + \gamma_0\int_0^t ds \sum_\nu\Delta_\nu(s) \phi(\boldsymbol{h}_\nu(s))\\ \end{align} \right. $$ であり、出力 $f_\mu(t)$ によって定まる $\Delta_\mu(t)$ を通して各成分が相互作用している。
これを解決するために、出力を決定するカーネルを主役にしよう。 ベクトル $\boldsymbol{h}_\mu(t), \boldsymbol{g}_\mu(t)$ の $N$ 個の成分が相互作用するのではなく、各成分が独立にカーネルと相互作用するという描像を導出し、同時にカーネルが決定論的になることを示す。 より具体的には、モーメント生成関数をベクトルからカーネルに変数変換して、カーネルの分布について鞍点法が使えることを確認する。 この鞍点方程式がカーネルの $O(1)$ の計算方法を与える。
モーメント生成関数をカーネルに変数変換する(クリックして表示)
まず、出発点となる $\boldsymbol{\chi}_\mu, \boldsymbol{\xi}$ のモーメント生成関数は次のとおり。 \begin{align} Z[\{\boldsymbol{j}_\mu\}_{\mu \in [P]}, \boldsymbol{v}] = \int \left(\prod_\mu \frac{d \boldsymbol{\chi}_\mu d \boldsymbol{\hat\chi}_\mu}{(2\pi)^N}\right) \frac{d \boldsymbol{\xi} d \boldsymbol{\hat\xi}}{(2\pi)^N} \exp\left(\sum_i f_1\left(\{\chi_\mu\}, \xi; j^\mu_i, v_i\right)\right) \end{align}
次に、$\boldsymbol{W}^0(0), \boldsymbol{w}^1(0)$ から $\boldsymbol{\chi}_\mu, \boldsymbol{\xi}$ に変数変換した時と同様に、$\delta$ 関数を使ってカーネルの定義式となる恒等式を導入する。 \begin{align} 1 &= N \int d\Phi^1_{\mu\alpha}(t,s) \delta\left(N \Phi^1_{\mu\alpha}(t,s) - \phi(\boldsymbol{h}_\mu(t)) \cdot \phi(\boldsymbol{h}_\alpha(s))\right) \\ &= Ndtds \int \frac{d\Phi^1_{\mu\alpha}(t,s)d\hat\Phi^1_{\mu\alpha}(t,s)}{2\pi i} \exp\left(dtds\hat\Phi^1_{\mu\alpha}(t,s)\left(N\Phi^1_{\mu\alpha}(t,s) - \phi(\boldsymbol{h}_\mu(t)) \cdot \phi(\boldsymbol{h}_\alpha(s))\right)\right) \\ 1 &= N \int dG^1_{\mu\alpha}(t,s) \delta\left(N G^1_{\mu\alpha}(t,s) - \boldsymbol{g}_\mu(t)\cdot\boldsymbol{g}_\alpha(s)\right) \\ &= Ndtds \int \frac{dG^1_{\mu\alpha}(t,s)d\hat{G}^1_{\mu\alpha}(t,s)}{2\pi i} \exp\left(dtds\hat{G}^1_{\mu\alpha}(t,s)\left(N G^1_{\mu\alpha}(t,s) - \boldsymbol{g}_\mu(t)\cdot\boldsymbol{g}_\alpha(s)\right)\right) \end{align}
続いて、全ての $\mu, \alpha, t,s$ に関する恒等式を、はじめの式の積分の内側に掛ける。 ただし $\boldsymbol{\chi}_\mu, \boldsymbol{\xi}$ に依存するのは $\boldsymbol{h}_\mu(t), \boldsymbol{g}_\mu(t)$ の部分だけなので、それ以外は積分の外に出す。 \begin{align} Z[\{\boldsymbol{j}_\mu\}_{\mu \in [P]}, \boldsymbol{v}] &\propto \int \prod_{\mu, \alpha, t, s} d\Phi^1 d\hat\Phi^1 dG^1 d\hat{G}^1 \exp\left(N\sum_{\mu, \alpha}\int dtds \left(\hat\Phi^1 \Phi^1 + \hat{G}^1 G^1\right)\right) \\ &\qquad \times \int \left(\prod_\mu \frac{d \boldsymbol{\chi}_\mu d \boldsymbol{\hat\chi}_\mu}{(2\pi)^N}\right) \frac{d \boldsymbol{\xi} d \boldsymbol{\hat\xi}}{(2\pi)^N} \exp\left\{\sum_i f_1\left(\{\chi_\mu\}, \xi; j^\mu_i, v_i\right)\right. \\ &\qquad\qquad - \left. \sum_{\mu, \alpha}\int dtds \left( \hat\Phi^1 \phi(\boldsymbol{h}_\mu(t)) \cdot \phi(\boldsymbol{h}_\alpha(s)) + \hat{G}^1 \boldsymbol{g}_\mu(t) \cdot \boldsymbol{g}_\alpha(s) \right) \right\} \\ \end{align} ただし例えば $\Phi^1 = \Phi^1_{\mu\alpha}(t,s)$ と略記している。 わかりにくいけど、$\Phi, G$ の積分と $\boldsymbol{\chi}_\mu, \boldsymbol{\xi}$ の積分は最後までかかっていることに注意。
最後に上の式をもう少し変形して $\boldsymbol{\chi}_\mu, \boldsymbol{\xi}$ の積分 を指数関数の中に入れると次のようになる。 (つまり$X=\exp(\log X)$ を使った。) \begin{align} Z[\{\boldsymbol{j}_\mu\}_{\mu \in [P]}, \boldsymbol{v}] &\propto \int \prod_{\mu, \alpha, t, s} d\Phi^1 d\hat\Phi^1 dG^1 d\hat{G}^1 \exp\left(NS[\Phi^1, \hat\Phi^1, G^1, \hat{G}^1]\right) \\ S[\Phi^1, \hat\Phi^1, G^1, \hat{G}^1] &= \sum_{\mu, \alpha}\int dtds \left( \hat\Phi^1 \Phi^1 + \hat{G}^1 G^1 \right) + \frac{1}{N} \sum_{i=1}^N \ln \mathcal{Z}_1[\{j^\mu_i\}_{\mu \in [P]}, v_i] \\ \mathcal{Z}_1[\{j^\mu_i\}_{\mu \in [P]}, v_i] &= \int \left(\prod_\mu \frac{d\chi_\mu d\hat\chi_\mu}{2\pi}\right) \frac{d\xi d\hat\xi}{2\pi} \exp\bigg\{ f_1\left(\{\chi_\mu\}, \xi; j^\mu_i, v_i\right) \\ &\qquad - \sum_{\mu, \alpha}\int dtds \left( \hat\Phi^1 \phi(h^\mu(t)) \phi(h^\alpha(s)) + \hat{G}^1 g^\mu(t) g^\alpha(s) \right) \bigg\} \end{align}
注目すべき点は4つある。
- $\delta$ 関数を挟んだことでベクトル $\boldsymbol{\chi}_\mu, \boldsymbol{\xi}$ とカーネル $\Phi^1, G^1$ が独立に扱えるようになった
- その結果、$\boldsymbol{h}_\mu, \boldsymbol{g}_\mu$ の各成分が出力を通じて相互作用するのではなく、各成分が独立にカーネルと相互作用するとみなせるようになった
- $\mathcal{Z}_1$ は1体のモーメント生成関数 $Z_1$ が歪んだ形である。歪みの原因はカーネルの定義式を $\delta$ 関数で表したことにある。
- 全体のモーメント生成関数 $Z$ は鞍点法が使える形になっている
(クリックして非表示)
鞍点法を使う(クリックして表示)
ここでいう鞍点法とは、ある汎函数が $y = \int dx \exp(Ng(x))$ のように表されている時の、$N\to\infty$ での近似法である。 $N$ が小さい時は広い範囲の $x$ が積分に寄与するが、$N$ が大きくなると $g(x)$ の最大値を与える $x$ の寄与が圧倒的になり、他の部分の寄与は無視できる。 したがって $y \sim \exp(Ng(x^*))$ と近似できる。ただし $x^*$ は $g(x)$ の最大値を与える $x$ であり、$\frac{dg(x)}{dx}|_{x=x^*} = 0$ を満たす。 定数倍はズレるけど今回は気にしなくてOK。
今の状況は、$Z \propto \int d\Phi^1 d\hat\Phi^1 dG^1 d\hat{G}^1 \exp\left(NS[\Phi^1, \hat\Phi^1, G^1, \hat{G}^1]\right)$ と表せていて、 $S$ が $O_N(1)$ の大きさを持つので、鞍点法が使える。具体的な鞍点方程式は以下の通り。 $$ \left\{ \begin{align} \frac{\delta S}{\delta \Phi^1_{\mu\alpha}(t,s)} &= 0 \to \hat\Phi^1_{\mu\alpha}(t,s) = 0 \\ \frac{\delta S}{\delta \hat\Phi^1_{\mu\alpha}(t,s)} &= 0 \to \Phi^1_{\mu\alpha}(t,s) = -\frac{1}{N} \sum_{i=1}^N \frac{ \partial \log\mathcal{Z}_1[\{j^\mu_i\}_{\mu \in [P]}, v_i] }{\partial \hat\Phi^1_{\mu\alpha}(t,s)} \\ \frac{\delta S}{\delta G^1_{\mu\alpha}(t,s)} &= 0 \to \hat{G}^1_{\mu\alpha}(t,s) = 0 \\ \frac{\delta S}{\delta \hat{G}^1_{\mu\alpha}(t,s)} &= 0 \to G^1_{\mu\alpha}(t,s) = -\frac{1}{N} \sum_{i=1}^N \frac{ \partial \log\mathcal{Z}_1[\{j^\mu_i\}_{\mu \in [P]}, v_i] }{\partial \hat{G}^1_{\mu\alpha}(t,s)} \\ \end{align} \right. $$
$\frac{\partial \log Z}{\partial x}$ というのは統計力学でよく見た形で、そう思うと $\mathcal{Z}_1$ はハミルトニアンが肩に乗っているように見える。 今回の場合に偏微分を実行すると例えば次のようになる。 \begin{align} \frac{\partial \log \mathcal{Z}_1[\{j^\mu_i\}_{\mu \in [P]}, v_i]}{\partial \hat\Phi^1_{\mu\alpha}(t,s)} &= -\langle \phi(h_\mu(t)) \phi(h_\alpha(s)) \rangle_{\{\chi_\mu\}, \xi} \end{align} ただし $\langle\rangle_{\{\chi_\mu\}, \xi}$ は $\mathcal{Z}_1$ の被積分関数で取った期待値である。 特にいま $\hat\Phi^1 = \hat{G}^1 =0$ なので、$\mathcal{Z}_1 = Z_1$ である。つまり $Z_1$ に入った歪みは鞍点法で解消される。 さらに $\boldsymbol{j}^\mu$ と $\boldsymbol{v}$ の各要素を等しくしたまま $0$ に近づけることで、それぞれの $i$ がidenticalになり、結局次の表式が得られる。 \begin{align} \Phi^1_{\mu\alpha}(t,s) &= \frac{1}{N}\sum_{i=1}^N \left\langle\phi(h_\mu(t)) \phi(h_\alpha(s))\right\rangle_{\{\chi_\mu\}, \xi} \\ &= \left\langle\phi(h_\mu(t)) \phi(h_\alpha(s))\right\rangle_{\{\chi_\mu\}, \xi} \\ G^1_{\mu\alpha}(t,s) &= \left\langle g_\mu(t) g_\alpha(s)\right\rangle_{\{\chi_\mu\}, \xi} \end{align}
余談だけど、鞍点法というより極値法と呼んだ方が実態に即していると思う。 どうして鞍点法と呼ぶかは分からない。
(クリックして非表示)
そうして得られた鞍点方程式は、巨視変数であるカーネルの $O(1)$ の計算方法を与える。 \begin{align} \Phi^1_{\mu\alpha}(t,s) &= \left\langle\phi(h_\mu(t)) \phi(h_\alpha(s))\right\rangle_{\{\chi_\mu\}, \xi} \\ G^1_{\mu\alpha}(t,s) &= \left\langle g_\mu(t) g_\alpha(s)\right\rangle_{\{\chi_\mu\}, \xi} \end{align}
ここで $\langle\rangle_{\{\chi_\mu\}, \xi}$ とは、$\boldsymbol{\chi} \sim \mathcal{N}(0,\boldsymbol{K}^x), \xi \sim \mathcal{N}(0,1)$ というガウシアンでの期待値である。(クリックして表示)
その理由を説明する。 一体問題のモーメント生成関数は次のようにさらに分解できる。 $$ \left\{ \begin{align} Z_1[\{j^\mu\}_{\mu \in [P]}, v] &= Z_1^\chi[\boldsymbol{j}] * Z_1^\xi[v] \\ Z_1^\chi[\boldsymbol{j}] &= \int \frac{d\boldsymbol{\chi}d \boldsymbol{\hat\chi}}{(2\pi)^P} \exp\left( i\boldsymbol{\hat\chi} \cdot \boldsymbol{\chi} - \frac{1}{2} \boldsymbol{\hat\chi}^\top \boldsymbol{K}^x \boldsymbol{\hat\chi} + \boldsymbol{j} \cdot \boldsymbol{\chi} \right) \\ Z_1^\xi[v] &= \int\frac{d\xi d\hat\xi}{2\pi}\exp\left( i\hat\xi \xi - \frac{1}{2}\hat\xi^2 + v \xi \right) \end{align} \right. $$ ベクトル $\boldsymbol{j}$ や $\boldsymbol{\chi}$ は長さ $N$ ではなく長さ $P$ であることに注意。 すなわち素子 $i$ ではなくデータ $\mu$ のインデックスを持つ確率変数である。 同様に $\boldsymbol{K}^x$ は $K_{\mu\alpha}^x$ を $(\mu, \alpha)$ 成分に持つ $P\times P$ 行列である。
これをよく見ると、$Z_1^\chi[\boldsymbol{j}]$ は $\boldsymbol{\chi} \sim \mathcal{N}(0,\boldsymbol{K}^x)$ の時のモーメント生成関数で、$Z_1^\xi[v]$ は $\xi \sim \mathcal{N}(0,1)$ の時のモーメント生成関数であることに気づく。 実際に、$\delta$ 関数のフーリエ変換表示 $$ \delta(\boldsymbol{\hat\chi}-i\boldsymbol{j}) = \int \frac{d\boldsymbol{\chi}}{(2\pi)^P} \exp(\boldsymbol{\chi}\cdot(i\boldsymbol{\hat\chi}+\boldsymbol{j})) $$ を用いて、 \begin{align} Z_1^\chi[\boldsymbol{j}] &= \int d\boldsymbol{\hat\chi} \delta(\boldsymbol{\hat\chi}-i\boldsymbol{j}) \exp\left(- \frac{1}{2} \boldsymbol{\hat\chi}^\top \boldsymbol{K}^x \boldsymbol{\hat\chi}\right) \\ &= \exp\left(\frac{1}{2} \boldsymbol{j}^\top \boldsymbol{K}^x \boldsymbol{j}\right) \end{align} と変形でき、これは $\boldsymbol{\chi} \sim \mathcal{N}(0,\boldsymbol{K}^x)$ の時のモーメント生成関数である。 したがって $\frac{\partial\log Z_1^\chi[\boldsymbol{0}]}{\partial \hat\Phi^1}$ は $\boldsymbol{\chi} \sim \mathcal{N}(0,\boldsymbol{K}^x)$ での期待値である。 $\xi$ についても同様。
振り返ってみるとモーメント生成関数を行列 $W$ からベクトル $\chi$、カーネル $\Phi$ へと変数変換して、カーネルのモーメント生成関数に鞍点法を使ったということ。 つまり、微視的なパラメータのランダムネスがあるが、巨視的なカーネルはrealizationによらず決定論的であるということ。
(クリックして非表示)
以上より、出力ダイナミクスを $O(1)$ の計算量で記述することができた。 $$ \left\{ \begin{align} \boldsymbol{\chi} &\sim \mathcal{N}(0,\boldsymbol{K}^x) \\ \xi &\sim \mathcal{N}(0,1) \\ h_\mu(t) &= \chi_\mu + \gamma_0\int_0^t ds \sum_\nu\Delta_\nu(s) g_\nu(s)K_{\mu\nu}^x \\ g_\mu(t) &= z(t) \dot\phi(h_\mu(t)) \\ z(t) &= \xi + \gamma_0\int_0^t ds \sum_\nu\Delta_\nu(s) \phi(h_\nu(s))\\ \Phi^1_{\mu\alpha}(t,t) &= \left\langle\phi(h_\mu(t)) \phi(h_\alpha(t))\right\rangle_{\boldsymbol{\chi}, \xi} \\ G^1_{\mu\alpha}(t,t) &= \left\langle g_\mu(t) g_\alpha(t)\right\rangle_{\boldsymbol{\chi}, \xi} \\ \frac{\partial f_\mu}{\partial t} &= \sum_\alpha \left(K_{\mu\alpha}^x G^1_{\mu\alpha}(t,t) + \Phi^1_{\mu\alpha}(t,t)\right) \Delta_\alpha (t) \\ \end{align} \right. $$
数値計算する場合は、まずガウス分布から $\boldsymbol{\chi}, \xi$ を多数サンプリングする。 次にそれぞれのサンプルを使って $h_\mu(t), g_\mu(t), z(t)$ の時間発展を1ステップ分計算する($\Delta$ は前の時刻までの $f$ で評価する)。 続いて $\Phi^1_{\mu\alpha}(t,t), G^1_{\mu\alpha}(t,t)$ のサンプル平均を求める。 最後に一番下の式を使って出力の時間発展を1ステップ分計算する。 以上を好きな $T$ まで繰り返す。
通常のDMFTとの違い(クリックして表示)
Crisanti & SompolinskyとかHelias & Dahmen で紹介されたような通常のDMFTでは、微視変数の時間発展の経路確率をMSRDJ表示して、そのモーメント生成関数を変形することで平均場のモーメント生成関数を得て、MSRDJ表示の逆変換によって平均場の時間発展を得るという方法が用いられていた。 それに対して今回の方法では、時間発展の確率性ではなく初期化の確率性に注目してモーメント生成関数を定義し、それを変形することでカーネルのモーメント生成関数を得て、鞍点法によってカーネルの表式を得た。 というわけで確率性の扱い方が普通のDMFTとは異なると思う。
一方で普通のDMFTと共通するのはモーメント生成関数(モーメント母関数)を導入して指数関数の肩でごちゃごちゃ変数変換するという点なので、「DMFTはお母さんの肩をもむ」という語呂合わせで覚えよう。
(クリックして非表示)
一般のLの場合
元論文の誤植
ページ数はarxivのv3のPDFファイルに準拠している。
| ページ | 行 | 誤 | 正 |
|---|---|---|---|
| 3 | 式(2)と(3)の間 | $K_{\mu\alpha}^{NTK}(t,s)=\nabla_\theta f_\mu \cdot \nabla_\theta f_\alpha$ | $K_{\mu\alpha}^{NTK}(t,s)=\gamma^2 \nabla_\theta f_\mu \cdot \nabla_\theta f_\alpha$ |
| 22 | 式(20) | $\Delta_\alpha(s)$ | $\Delta_\mu(s)$ |
| 22 | 式(21)の1行目 | $\boldsymbol{g}_\nu^{l+1}(t)$ | $\boldsymbol{g}_\mu^{l+1}(s)$ |
| 22 | 式(22) | $\boldsymbol{\chi}_\mu^l(t)$ | $\boldsymbol{\chi}_\nu^{l+1}(t)$ |
| 23 | 式(25)の1行目 | $\frac{1}{\sqrt{N}}$ | $\frac{1}{\sqrt{D}}$ |
| 23 | 式(26) | $d\boldsymbol{\chi}d\hat{\boldsymbol{\chi}}$ | $d\boldsymbol{\chi}_\mu d\hat{\boldsymbol{\chi}}_\mu$ |
| 23 | 式(27)の1行目 | $\exp\left(N\hat{\Phi}_{\mu\alpha}(t,s)\dots\right)$ | $\exp\left(\hat{\Phi}_{\mu\alpha}(t,s)\dots\right)$ |
| 23 | 式(27)の3行目 | $\exp\left(N\hat{G}_{\mu\alpha}(t,s)\dots\right)$ | $\exp\left(\hat{G}_{\mu\alpha}(t,s)\dots\right)$ |
| 25 | 式(36)の1行目 | $W^{l}(0)$ | $W^{0}(0)$ |
| 25 | 式(36)の4行目 | $g_\mu^{l}(t)$ | $g_\mu^{l+1}(t)$ |
| 25 | 式(37)の4行目 | $\int_0^\infty$ | $\int_0^\infty dt$ |
| 26 | 式(38)の4行目 | $\boldsymbol{\hat\chi}_\mu^{l+1}(t) \cdot \boldsymbol{\hat\chi}_\mu^{l+1}(t)$ | $\boldsymbol{\hat\chi}_\mu^{l+1}(t) \cdot \boldsymbol{\hat\chi}_\alpha^{l+1}(s)$ |
| 26 | 式(39) | $\Phi_{\mu, \alpha}^{l}(t, s)$ | $\Phi_{\mu\alpha}^{l}(t, s)$ |
| 27 | 式(43) | $\langle \hat{g}_\mu^l(t) \hat{g}_\alpha^l(s) \rangle$ | $\langle \hat{\xi}_\mu^{l-1}(t) \hat{\xi}_\alpha^{l-1}(s) \rangle$ |
| 28 | 式(45)の1行目 | $\langle \boldsymbol{\hat\chi}^{l+1} \boldsymbol{\hat\chi}^{l+1} \rangle$ | $\langle \boldsymbol{\hat\chi}^{l+1} \boldsymbol{\hat\chi}^{l+1\top} \rangle$ |
| 28 | 式(46)の1行目 | $\langle \boldsymbol{\hat\xi}^{l} \boldsymbol{\hat\xi}^{l} \rangle$ | $\langle \boldsymbol{\hat\xi}^{l} \boldsymbol{\hat\xi}^{l\top} \rangle$ |
| 28 | 式(46)の1行目 | $i\boldsymbol{\hat{r}} \cdot \boldsymbol{\hat{\xi}}^l$ | $i\boldsymbol{r} \cdot \boldsymbol{\hat{\xi}}^l$ |
| 28 | 式(47)の2行目 | $\phi(\boldsymbol{h})$ | $\phi(\boldsymbol{h}^l)$ |
| 28 | 式(47)の2行目 | $()$ | $()^\top$ |
| 28 | 式(49)の1行目 | $\hat\chi_\mu^{l+1}(t)$ | $\hat\chi_\mu^{1}(t)$ |
| 28 | 式(49)の4行目 | $\hat\xi_\mu^{l}(t)$ | $\hat\xi_\mu^{L}(t)$ |
| 28 | 式(49)の4行目 | $\hat\xi_\mu^{l}(t)$ | $\hat\xi_\mu^{L}(t)$ |
| 28 | 式(49)の4行目 | $\hat\xi_\mu^{l}(t)$ | $\hat\xi_\mu^{L}(t)$ |
| 29 | 式(51)の1行目 | $-\frac{1}{2} \langle \boldsymbol{\hat\chi}^{l+1} \boldsymbol{\hat\chi}^{l+1\top} \rangle$ | $\frac{1}{2} \langle \boldsymbol{\hat\chi}^{l+1} \boldsymbol{\hat\chi}^{l+1\top} \rangle$(以降も符号が逆) |
| 29 | 式(52) | $\exp(i \boldsymbol{j}^{l} \cdot \boldsymbol{\chi}^{l} + i \boldsymbol{v}^{l} \cdot \boldsymbol{\xi}^{l} )$ | $\exp(\boldsymbol{j}^{l} \cdot \boldsymbol{\chi}^{l} + \boldsymbol{v}^{l} \cdot \boldsymbol{\xi}^{l} )$ |